AMUSE v3リリース

2025/4/16に、v3.0.1 がリリースされました!

さっそく、どんなところが変わったのか、変わっていないのかチェックしてみました。
公式サイトより
- AMD 最適化 ONNX モデル
- SDXL ControlNet: Canny、SoftEdge、OpenPose、Depth など
- SDXLサポートによるインペインティングの改善
- よりスマートなメモリ管理でパフォーマンスを向上
- タイリングサポートによる無限のアップスケーリング
- locomotion: テキストからビデオの生成をサポート
- よりスマートなモデルのダウンロード: キューイングと失敗時の再開
利用には AMD Driver 24.30.31.05 ま�たはそれ以上が必要です。
インストールは簡単
以前と同様、インストーラをダウンロードして実行するだけです。
モデルのダウンロードに時間はかかりますが、操作としてはとてもシンプルで素晴らしいです!
モデルが増えた
なんと、127種類のモデルが使えるようになりました!
スペックが足りなくて使えないものや、イマイチ使い道のないモデルなんかもありますが。
単純に選択肢が増えたのは良いことだと思います!
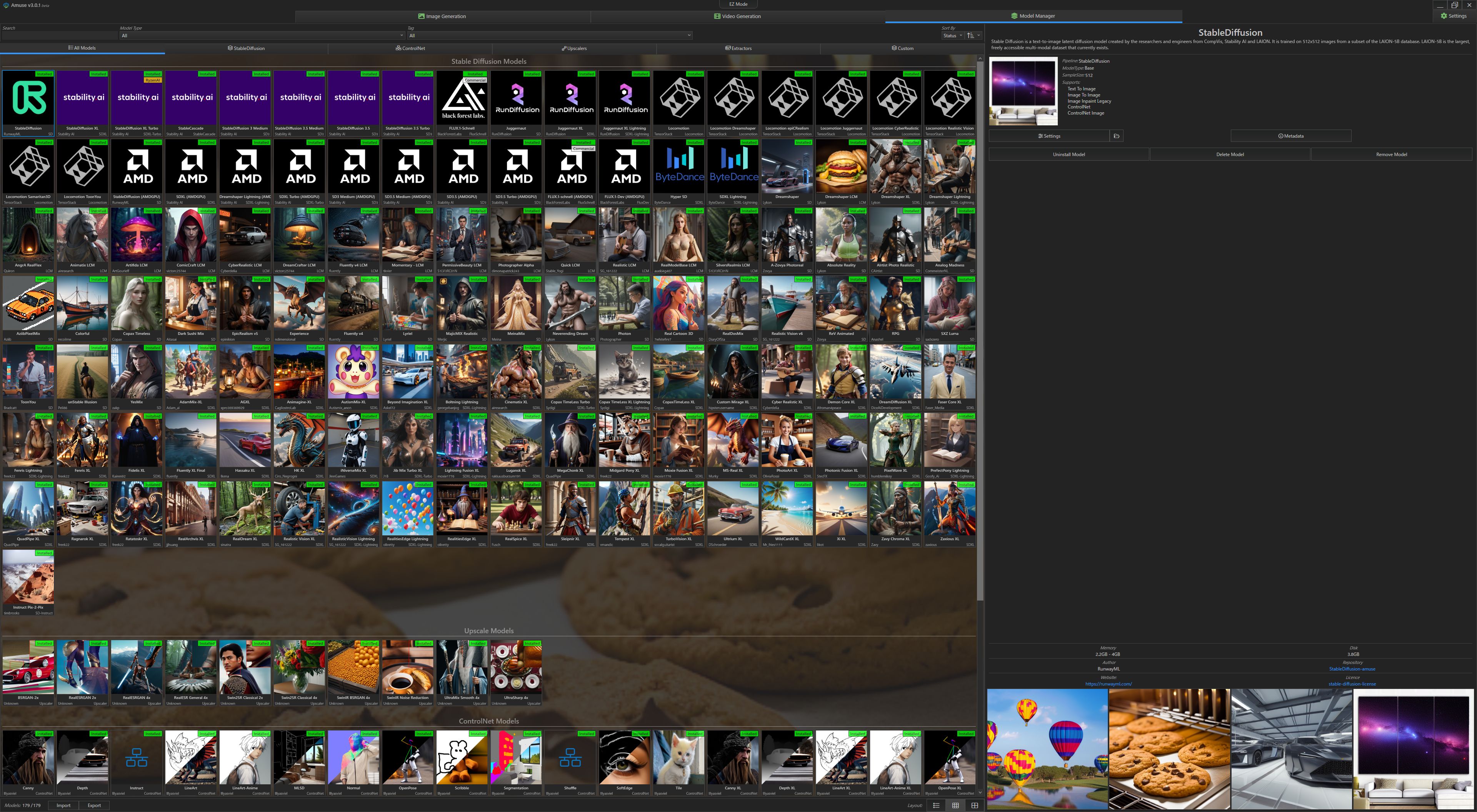
v2とv3でモデルの互換性がない
地味に不便。
モデルダウンロードし直し・・・
ムキになって全部ダウンロードしたら1TB超えました。
マンションの細い100Mbps回線で30時間以上かかりましたよ・・・
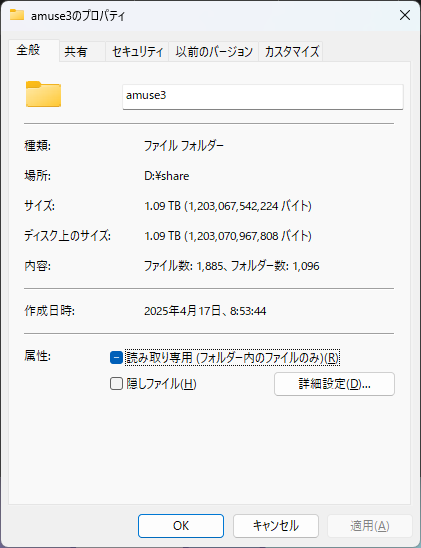
これはモデル、controlNet、upscalerなど全部含めたサイズです(アプリ本体は別)。
モデルのダウンロード管理が便利になった
そのモデルですが、ダウンロードの管理が少し楽になっています。
v2まで
- 1つずつダウンロードする
- 1つダウンロードが終わったら次のダウンロードを操作
- ダウンロード中に生成できない
v3
- 1つずつ選択していくが、予約としてキューに入れて置けるようになった
- 一括でキューにいれることはできない、1つずつagreeする必要がある
- 生成中でもバックグラウンドでダウンロードしてくれる
- なぜか
Model Managerの画面だとCPU負荷があがるっぽいので別画面で待機するのが良さそう
このように、v3ではダウンロード管理が使いやすく進化しました。
動画生成
テキストから短い動画を作成できます!
サイバーパンク猫のプロンプトで出力してみました。モデルは Locomotion Juggernautです。
80秒ほどで短い動画を生成してくれました。
youtubeにアップしています。
なかなか良い出来だと思いませんか?
生成サイズのプリセットが増えた
デフォルトでは正方形サイズしか選べなかったのが、縦横比率によってプリセットが増えています。
縦長、横長の画像をより簡単に生成しやすくなりました。

その他
- モード名称が
Advanced→Expartに変更 - 処理実行中のカウンタ更新インターバルが短くなった
相変わらずな点
v2 から引き継がれたちょっと不満な点です。
なんとかならないものか。
Auto saveのファイル名を設定できない- どんな条件で出したかファイルから復元できない
- pngの中にプロンプトやモデル名を入れてくれればなお良い
- モデル名の並びがインストール順で探しにくい
- なんでソート機能ないの・・・
- NSFWブロック(生成結果をAIがNSFW判定してぼかし処理する)
RyzenAI NPUを活用してくれるモデルは増えてない
おわりに
細かい改善や、モデルが増えたことなど正当に進化していると感じました。
またモデルごとの出力比較などで遊んでみたいと思います!